丂偙偺崁栚偼丄椙彂偱偁傞儅儞僈偱暘偐傞摑寁妛[夞婣暘愅曇]偵偮偄偰丄
丂乽傛傝幚慔揑乿傪栚巜偟曗懌偡傞傕偺偱偡丅
丂埲慜傕彂偒傑偟偨偑丄偙偺恾彂偼夞婣暘愅傪悢妛偺堦僕儍儞儖偲偟偰徯夘偟偰偍傝丄
丂巆擮側偑傜乮彂柺偺娭學傕桳傞偺偱偟傚偆偑乯丄幚慔揑側懁柺偑慜柺偵弌偰偄傑偣傫丅
丂僗僩乕儕乕偺僔僠儏僄乕僔儑儞偐傜丄乽偳偺傛偆側応柺偱桳塿偐乿偼棟夝偱偒傑偡偑丄
丂偱偼偦偺條側僔僠儏僄乕僔儑儞偵憳嬾偟偨偲偒偵丄偙偺杮傪撉傫偩恖偑
乽偱偼丄夞婣暘愅傪巊偭偰傒傛偆両乿
丂偲巚偆偐偲尵偊偽丄巆擮側偑傜偦傫側帠偼側偄偱偟傚偆丅偲偄偆偺傕丄
丂寁嶼僾儘僙僗偑斚嶨偱偁傞夞婣暘愅偺暘愅僾儘僙僗偲丄摼傜傟傞岠梡傪斾妑偟偨偲偒丄
丂暘愅偵學傞楯椡偼柧傜偐偵岠梡傪壓夞偭偰偄傞偲梊憐偝傟偰偟傑偆偐傜偱偡丅
丂悢妛傪妛傇恖丄傑偨偼悢妛幰偼夞婣暘愅傪峴偆帠帺懱偑栚揑偩偐傜偄偄偺偱偟傚偆偑丄
丂変乆偺傛偆側幮夛恖偵偲偭偰偼丄夞婣暘愅偼僣乕儖偱側偔偰偼側傝傑偣傫丅
丂僣乕儖偼丄枩恖偑巊偄偙側偣偰偙偦堄枴偑偁傞傕偺偱偼側偄偱偟傚偆偐丅
丂岾偄側帠偵丄夞婣暘愅傪娙扨偵幚慔偱偒傞娐嫬傪丄変乆偱傕庤偵擖傟傞帠偑壜擻偵側傝傑偟偨丅
丂偦偺娐嫬偲偼丄僄僋僙儖偱偡丅偍偦傜偔丄偙偺僒僀僩傪尒傟傞恖慡偰偑丄偁偺暋嶨夦婏偵尒偊傞
丂夞婣暘愅傪丄偝傜傝偲傗偭偰偺偗傞偙偲偑偱偒傑偡丅偙傫側帠丄杔偑戝妛惗傫偲偒偵偼憐憸
丂偱偒傑偣傫偱偟偨偑丄悽偺拞偺恑曕偲偄偆偺偼丄杮摉偵惁偄傕偺偱偡偹丅
丂仸惓妋偵尵偆偲丄摉帪偐傜僄僋僙儖偵偼偦偺婡擻偑旛傢偭偰偄傑偟偨偑丄
丂丂偦傫側偙偲傪嫵偊偰偔傟傞恖偼戝妛偵偼偄側偐偭偨乧擔杮偺戝妛偼杮摉偵僟儊偱偡偹
丂偱偼丄憗懍偱偡偑丄僄僋僙儖傪巊偭偰偺暘愅曽朄傪徯夘偟偰峴偒偨偄偲巚偄傑偡丅
丂嵟弶偵丄壓婰偺庤弴傪傆傒丄暘愅偺弨旛傪偟傑偡丅偦傫側偵擄偟偄帠偱偼桳傝傑偣傫丅
丒僄僋僙儖傪婲摦丅乽僣乕儖乿仺乽傾僪僀儞乿仺暘愅僣乕儖傪慖戰仺俷俲
丂偙傟偱丄摑寁暘愅傪娙扨偵峴偊傞僣乕儖偑僄僋僙儖偵慻傒崬傑傟傑偟偨丅
丂偮偄偱偵丄僜儖僶乕側傫偐傕曻傝崬傫偱偍偒傑偟傚偆丅摑寁僣乕儖偲僜儖僶乕偼丄
丂僄僋僙儖偵旈傔傜傟偨嫮椡僆僾僔儑儞偺昅摢奿偱偡丅
丂亙乽暘愅僣乕儖乿摫擖偺僗僋儕乕儞僔儑僢僩亜
丂偱偼丄憗懍暘愅傪偟偰傒傑偟傚偆丅惓捈側偲偙傠丄媡娭悢偩偺帺慠懳悢側偳偼丄
丂偙偺帪揰偱偼堄幆偡傞昁梫偼桳傝傑偣傫丅戝愗側偺偼丄
丒倷偲偄偆帠徾偼丄倶偲偄偆帠徾偵塭嬁偝傟偰偄偐傕偟傟側偄偵傖乕
丂偲捈姶偱憐憸偡傞帠偱偡丅幃偱尵偆偲丄倷亖倎倶亄倐乮亄剈乯偲昞尰偝傟傑偡丅
丂倎偲倐偼丄偦傟偑乽偳偺掱搙乿塭嬁偟偰偄傞偐丄偲偄偆帠偱偡偹丅
丂偪側傒偵丄倎偼曽掱幃偺孹偒偱偡偐傜丄乽塭嬁搙偺曄摦搙崌偄乿傪偁傜傢偟偰偍傝丄
丂倐偼愗曅偱偡偐傜丄乽強梌偺塭嬁搙乿傪昞偟偰偄傞偲偄偊傑偟傚偆丅
丂仸乮亄e乯偺晹暘偼丄僄儔乕乧偮傑傝丄岆嵎偱偡丅摑寁妛偼姰慡偱偼側偄偨傔丄
丂丂暘愅寢壥偑侽亾丄侾侽侽亾埲奜偺応崌偼昁偢偙偺崁偑懚嵼偟傑偡丅
丂丂杮彂偱偼徣棯偝傟偰偍傝丄乽偖傜偄乿偲偄偆奣擮偱昞尰偝傟偰偄傑偡偑丄
丂丂堦墳堄幆偡傞傛偆偵偟偰偔偩偝偄丅
丂側偍丄偙偙偱偼廳夞婣偐傜偺夝愢偲側傝傑偡偑丄庤朄偱夞婣偲偺憡堘偼偁傝傑偣傫丅
丂孹偒偑暋悢偵側傞偐丄堦偮偵側傞偐丄偩偗偺嵎偱偡丅
丂偱偼巒傔傑偟傚偆丅丄杮摉偵丄倶乮偨偪乯偑倷偵塭嬁傪梌偊偰偄傞偺偱偟傚偆偐丠
丂偦傟偼丄尰抜奒偱偼扤偵傕暘偐傝傑偣傫丅偦傟傕暘愅偡傞偺偑丄夞婣暘愅偱偡丅
丂偟偐偟丄丄傑偢弶傔偵戝愗側偺偼丄乽忢幆乿偲偄偆嬌傔偰摉偨傝慜偺姶妎偱偡丅
丂倶傪庢幪慖戰偡傞偵偁偨傝丄側傫偱傕梫場傪堷偭挘偭偰偔傞偺偼丄嬸偺崪捀偱偡丅
乽倶偼倷偵塭嬁傪梌偊偰偄偦偆偩乿
丂偲偄偆姶妎偑丄廳梫両壖掕傪抲偔偺偼彑庤偱偡偟丄暘愅偡傞偺傕彑庤偱偡偑丄
乽嬤強偺彫妛峑偺弌寚忬嫷乮亖倶乯偑丄僲儖儞偺傾僀僗僥傿乕偺拲暥悢乮亖倷乯偵塭嬁乿
丂偲偄偆壖掕傪抲偄偨偲偟偰傕丄傫側崁栚娫偵娭楢偑柍偝偦偆側偺偼丄忢幆偱暘偐傝傑偡丅
丂杮彂偱偼丄婥壏偲傾僀僗僥傿乕偲偄偆娭學傪摉偨傝慜偺傛偆偵庢傝忋偘偰偄傑偡偑丄
丂偙偺忢幆傒偨偄側娭學傪捦傓丒攃埇偡傞帠偑戝愗側偺偱偡丅
丂忢幆偲偄偆偺偼丄堄奜偲戝愗側姶妎偱偡偐傜丄擔崰偐傜杹偐側偔偰偼側傝傑偣傫偹丅
丂傑偀丄偦傟偼擔乆偺尋鑢偵嬑傔傞偲偟偰丄暘愅偱偡丅
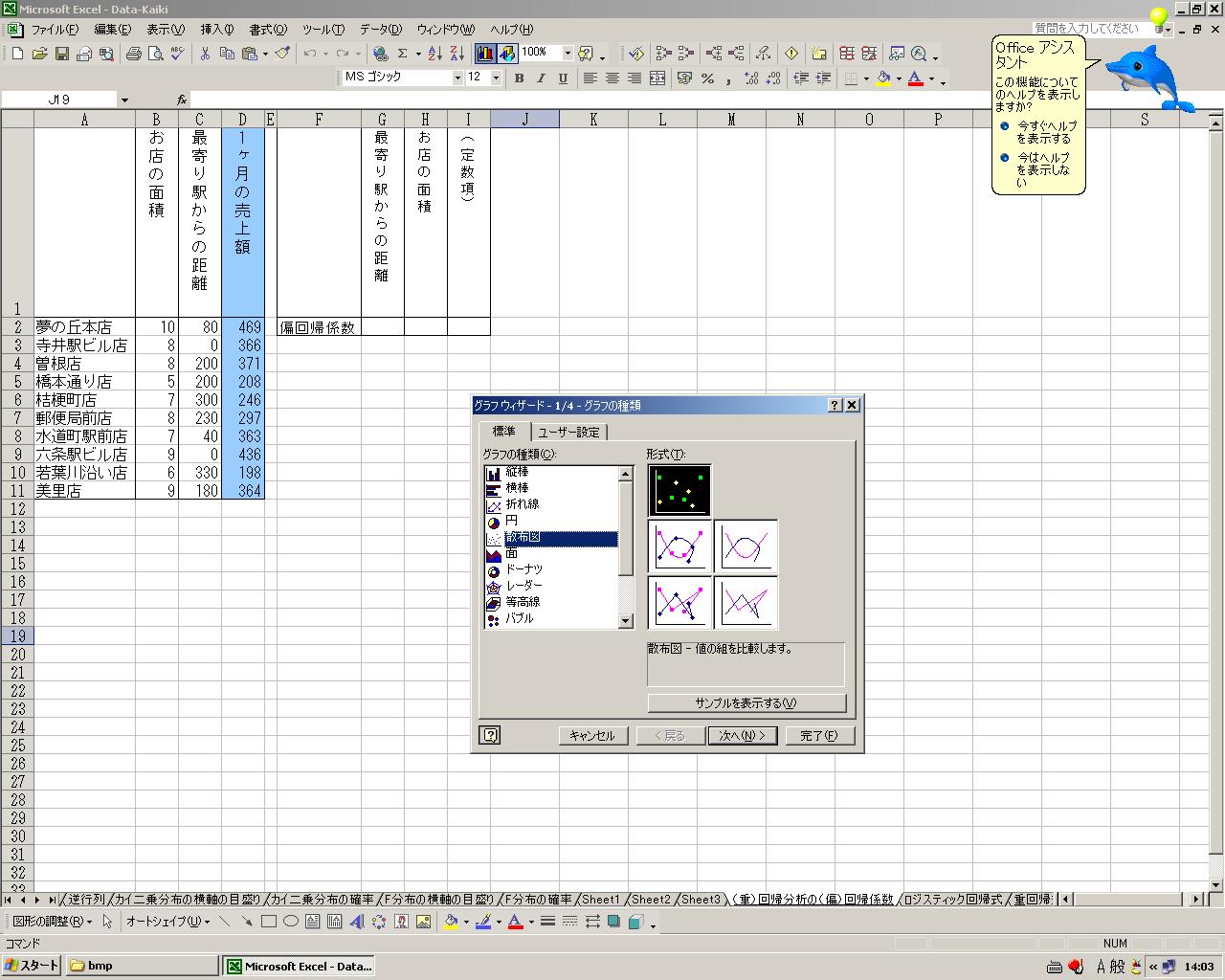
丂傑偢偼丄杮彂偺偍擇恖偑傗偭偰偄傞傛偆偵丄僌儔僼傪偮偔傝傑偟傚偆丅
丂庤偱彂偔偺傕偄偄偱偡偑丄偙傟偙偦僄僋僙儖偺摼堄拞偺摼堄偱偡偺偱丄擟偣傑偟傚偆丅
丒乽僌儔僼僂僀僓乕僪乿傾僀僐儞傪僋儕僢僋仺乽嶶晍恾乿仺堦斣忋偺宍幃傪慖戰
丂仺倶偑倶幉偵丄倷偑倷幉偵棃傞傛偆偵僌儔僼傪嶌惉
丂亙乽僌儔僼乿嶌惉曽朄偺僗僋儕乕儞僔儑僢僩亜
丂亙乽僌儔僼乿寢壥偺僗僋儕乕儞僔儑僢僩丒偦偺侾亜
丂偙傟偱嶶晍恾偑弌棃傑偟偨丅側傫偲側偔憡娭惈偑偁傝偦偆側偺偑暘偐傝傑偡偹丅
丂帺暘偺忢幆儗儀儖偵擺摼偟偮偮丄崱搙偼偙傟傪悢帤偱棫徹偟偰傒傑偟傚偆丅
丂偙傟偵偼丄乽憡娭乿傪巊偄傑偡丅
丒乽僣乕儖乿仺乽暘愅僣乕儖乿仺乽憡娭乿
丂擖椡斖埻偱丄偛偦偭偲悢抣傪慖傃傑偡丅堦斣忋偵儔儀儖偑偁傝丄偦偙傕斖埻偵慖戰偟偨応崌偼丄
丂乽愭摢峴傪儔儀儖偲偟偰巊梡乿傕僋儕僢僋偟偰偍偒傑偟傚偆丅
丂亙乽憡娭乿憖嶌偺僗僋儕乕儞僔儑僢僩丒偦偺侾亜
丂亙乽憡娭乿憖嶌偺僗僋儕乕儞僔儑僢僩丒偦偺俀亜
丂亙乽憡娭乿昞帵偺僗僋儕乕儞僔儑僢僩亜
丂偙傟偱丄暿僔乕僩偵倶偲倷偺憡娭偑昞帵偝傟傑偟偨丅
丂攧忋偘偲偦偺懠偺娭學偼丄嬌傔偰侾乮倧倰亅侾乯偵嬤偄悢抣丄偐側傝娭學偼崅偦偆丅
丂偙傟偖傜偄偺悢帤偑弌傟偽丄夞婣暘愅偺傗傝偑偄傕偁傝偦偆丄偲偄偊傑偟傚偆丅
丂側偍丄偙偙偱侽丏俆偱偁傟偽丄偆乕傫乧偲柪偭偰偔偩偝偄丅幪偰傞傕廍偆傕婱曽師戞偱偡丅
丂偙偆偄偆偲偙傠偱丄傑偨忢幆傪摥偐偣傑偡丅侽丏俁偖傜偄側傜幪偰傑偟傚偆丅
丂偪側傒偵丄杮彂偱偼愢柧偟偰偄傑偣傫偑丄儅僀僫僗偺応崌偼晧偺憡娭偲偄偄丄
丂悢帤偑斀懳曽岦偵摦偔尰徾傪尵偄傑偡丅梫偡傞偵丄岲偒岲偒戝岲偒両偭偰傾僺乕儖偡傞偲丄
丂岦偙偆傕偳傫偳傫偙偭偪傪岲偒偵側偭偰偄偔応崌偲丄僂僓偔偰寵偄偵側偭偰偄偔応崌丄
丂椉曽偁傞偭偰偙偲偱偡偹丅
丂偝偰丄偮偓偼丄偄傛偄傛夞婣暘愅偱偡丅
丒乽僣乕儖乿仺乽暘愅僣乕儖乿仺乽夞婣暘愅乿
丂擖椡斖埻偱丄倷偵憡摉偡傞悢抣孮傪乽擖椡倄斖埻乿丄倶憡摉傪乽擖椡倃斖埻乿偱巜掕丅
丂僨僼僅儖僩偱桳堄悈弨偼俋俆亾偵側偭偰偄傑偡偑丄偍岲傒偱曄峏偟傑偟傚偆丅
丂堦斣忋偵儔儀儖偑偁傝丄偦偙傕斖埻偵慖戰偟偨応崌偺懳墳偼丄憡娭偺偲偒偲摨條偱偡丅
丂亙乽夞婣暘愅乿憖嶌偺僗僋儕乕儞僔儑僢僩丒偦偺侾亜
丂亙乽夞婣暘愅乿憖嶌偺僗僋儕乕儞僔儑僢僩丒偦偺俀亜
丂俷俲傪墴偡偲丄傕偆寁嶼寢壥偑偱傑偟偨両側傫偲娙扨側傫偱偟傚偆偐丄價僢僋儕偱偡丅
丂杮彂偲摨偠庤弴傪摜傒側偑傜丄寁嶼傪堄幆偡傞偙偲側偔偙偙傑偱弌棃傞偺偱偡丅
丂暥柧偭偰偡偛偄偱偡偹偉丅
丂偱偼丄昞偺尒曽傪夝愢偟傑偡丅
丂仸昞偼丄帺暘偱嶌偭偰傒偰偔偩偝偄丅偦偺傎偆偑曌嫮偵側傝傑偡偺偱
丂堦斣忋偺乽夞婣摑寁乿偵廳寛掕俼俀乮偍傛傃曗惓俼俀乯偑弌偰偄傑偡偺偱丄
丂傑偢偼儌僨儖偺懨摉惈偑堦栚偱暘偐傝傑偡丅杮彂偺儌僨儖偼側偐側偐偱偡偹丅
丂師偺暘嶶暘愅昞偱偡偑丄偙偙偱拲栚偡傞偺偼塃抂偺乽桳堄俥乿丅
丂昁梫偵敆傜傟偨傜暘嶶側偳傕尒傑偡偑丄杔偺姶妎偱尵偆偲丄幚柋偱偼俀擭娫偱
丂侾搙傕懠偺悢帤傪巊偭偨帠偑偁傝傑偣傫丅偦偺掱搙偺悢抣偲巚偭偰偔偩偝偄丅
丂嵟屻偵丄孹偒偲愗曅丄偮傑傝丄悢幃偱尵偆偲倎偲倐丄偺晹暘偑昞偵側偭偰偄傑偡丅
丂倎偼乽倃抣乿偺乽學悢乿丄倐偼愗曅偺乽學悢乿偱偡丅偲傝偁偊偢塃抂傑偱僕儍儞僾偟丄
丂忋尷倶倶亾丄壓尷倶倶亾乮倶倶偼桳堄悈弨乯偵昞帵偝傟傞悢帤偑丄怣棅嬫娫偲側傝傑偡丅
丂梫偡傞偵丄乽學悢乿傪拞怱偲偟偰乽忋尷乿偲乽壓尷乿偺娫偵丄俋俆亾偁傝偆傞偩傠偆
丂悢抣偑擖傞丄偲偄偆偙偲偱偡偹丅昞偺拞墰偵丄乽倲乿乽俹抣乿偺悢帤偑偁傝傑偡偑丄
丂偙傟偼偲傝偁偊偢柍帇偟偰偔偩偝偄丅屻偱丄巊偆偲偒偵夝愢偟傑偡丅
丂偙傟偱丄夞婣暘愅偺幃偑敾柧偟傑偟偨両
丂偝偰丄夞婣傪憱傜偣偨傜丄偙偺儌僨儖偺桳岠惈傪妋擣偟傑偡丅
丂偙傟偼丄杮彂偵偁傞傛偆偵丄婣柍壖愢傪梡偄偰偺専掕傪峴偆偙偲偵側傝傑偡丅
丂偑丅乽婣柍壖愢乿乽専掕乿偩偺丄柍棟栴棟榓栿偟偨傛偆側尵梩偼柍帇偡傞偵尷傝傑偡丅
丂戝愗側偺偼丄偳偺傛偆偵儌僨儖偺桳岠惈傪専徹偡傞偐棟夝偡傞帠偱偼側偄偱偟傚偆偐丅
丂嵟弶偵丄拞墰丒暘嶶暘愅昞偺塃抂丄乽桳堄俥乿傪傒傑偟傚偆丅
丂侽丏侽俆傛傝嬌傔偰彫偝偄悢帤偑昞帵偝傟偰偄傞偲巚偄傑偡丅偙傟偱乽俷俲乿偱偡丅
丂桳堄悈弨傪愝掕偟丄侾偐傜偦傟傪堷偄偨悢埲壓側傜俷俲丄偦偆夝庍偟偰偔偩偝偄丅
丂乧壗偑偳偆俷俲側傫偩丄偲巚偄傑偡偐丠偱偼丄儚働傪夝愢偟傑偟傚偆丅
丂嵟弶丄桳堄悈弨傪俋俆亾偲愝掕偟丄俋俆亾亖侽丏俋俆側偺偼暘偐傞偲巚偄傑偡丅
丂婣柍壖愢傪棫偰偨偲偒丄婣柍壖愢傪嵦梡偡傞偺傪丄偙偺俋俆亾偲偟偨栿偱偡丅
丂偱偡偐傜丄偙偺俋俆亾埲撪偵擖偭偰偄側偗傟偽丄婣柍壖愢傪婞媝偡傞帠偵側傝傑偡丅
丂偙偺応崌偼丄擖偭偰偄側偄帠偑乽桳堄俥乿偺悢帤偐傜暘偐傝傑偡偺偱丄婣柍壖愢婞媝丄
丂懳棫壖愢乮亖帺暘偺帩偭偰偄傞壖愢乯偺惓摉惈偑幚徹偑偝傟偨栿偱偡丅
丂廳夞婣偺応崌偵偼丄奺孹偒偵晅偄偰傕丄惓摉惈偺妋擣傪偟傑偡丅
丂仸傕偭偲捈姶揑偵夝愢偟傑偟傚偆丅偙傟偼惓偟偄夝愢偱偼桳傝傑偣傫偑丄奣擮揑偵丅
丂丂専掕偼丄帺暘偺壖愢傪嬌傔偰尩偟偄棫応偵捛偄崬傒丄偦傟偱傕惉棫偡傞傫偩傛丄
丂丂偲夝愢偱偒傞忬懺傪徹柧偟傑偡丅傑偢丄専掕傪侽亾偐傜僗僞乕僩偝偣偰丄俆亾傪
丂丂挻偊側偗傟偽帺暘偺壖愢偑惓偟偔丄偦傟埲忋偺悢抣偵側偭偰偟傑偭偨傜傾僂僩丄
丂丂婣柍壖愢傪嵦梡偟丄儌僨儖慡偰傪乽柍偵婣偡乿昁梫偑偁傞偺偱偡丅偙偙偱偼丄
丂丂俆亾傪挻偊偰側偄偺偱丄儌僨儖傪柍偵婣偡昁梫偑側偄丄偲偄偆帠偱偡偹丅
丂偱偼丄奺孹偒偺惓摉惈傕妋擣偟偰偟傑偄傑偟傚偆丅偙傟傕婣柍壖愢傪梡偄傑偡偑丄
丂偄傑傑偱偲斾傋偰摿抜堄幆偡傞昁梫偼偁傝傑偣傫丅傗傞偙偲偼桳堄俥偺偲偒偲摨偠偱偡丅
丂孹偒偺専徹偵偼丄堦斣壓偺昞偺乽俹抣乿乽倲乮専掕乯乿偺偄偢傟偐傪棙梡偟傑偡丅
丂偳偪傜偱傕摨偠寢壥偵側傝傑偡偑丄乽桳堄俥乿偲摨偠條偵峫偊傜傟傞俹抣傪傑偢尒傑偡丅
丂侽丏侽俆埲壓偱偡偹丠俷俲偱偡丅偁偲偼丄桳堄俥偺夝愢偲摨偠偱偡丅
丂乮晛捠偺夞婣暘愅偱偼丄桳堄俥偲孹偒偺俹抣偑堦抳偟偰偄傞偼偢偱偡傛乯
丂偱偼丄乽倲乿偲偼壗側偺偱偟傚偆偐丅偙傟偼丄愭傎偳偺俹抣側傝偺悢帤偑丄
丂惓婯暘晍偵偍偄偰廤崌偺拞墰偐傜丄偳傟偩偗偺嫍棧偺強偵偁傞偐傪昞偟偨悢帤偱偡丅
丂惓婯暘晍偱偼丄廤崌偺俋俆亾偑廂傑傞嫍棧偼嵍塃偵1.96偱偡偐傜丄亇1.96埲忋偱偁傟偽丄
丂偦偺悢帤偼廤崌偺俆亾偺曽偵懏偡傞帠偑暘偐傝傑偡丅偪側傒偵丄倲偼俹抣傊埲壓偺幃偱
丂曄姺壜擻偱偡乧亖俿俢俬俽俿(倲抣,帺桼搙,俀)
丂偙傟偱丄夞婣乛廳夞婣暘愅偼廔椆偱偡両
丂偁偲偼丄偙偺幃傪巊偭偰擟堄偺悢傪戙擖偟丄寢壥偺梊憐傪峴偆偺傒偲側傝傑偡丅
丂側傫偰暘偐傝傗偡偄両偨偭偨偙傟偩偗偺偙偲偱丄偁偺杮堦嶜暘偺偙偲偑弌棃傞傢偗偱偡丅
丂偆乕傫丄巊傢側偄偲傕偭偨偄側偄丄偖傜偄偵巚偊偰偒傑偣傫偐丠
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}